<SQL> データ加工
重複データを省く
特定のカラムの重複を省くとき、以下の構文を使用する。
SELECT DISTINCT (カラム名) FROM テーブル名;
<例>

SELECT DISTINCT(name) FROM account;
結果
↓

四則演算によるカラムデータの再計算
消費税など、既存のカラム値に数値に変更を加えたい場合はこの方法を使用する。
SELECT カラム名 四則演算(+-*/) 数値 FROM テーブル名;
<例>税込み価格の算出
SELECT name, price, price*1.10 FROM account;
結果
↓

集計関数
SUM関数:
WHEREで検索したデータを集計。
<例>ランチ金額の合計
SELECT SUM(price),name FROM account WHERE name = "ランチ";
結果
↓

AVG関数:
WHEREで検索したデータの平均を算出。
<例>ランチ金額の平均
SELECT AVG(price),name FROM account WHERE name = "ランチ";l
結果
↓

COUNT関数:
WHEREで検索したデータの数を集計。
nullはカウントされないので、nullをカウントしたいときは
SELECT COUNT(*)
にする。
<例>ランチの回数
SELECT COUNT(name),name FROM account WHERE name = "ランチ";
結果
↓

MAX,MIN関数:
MAXは最大値、MINは最小値を取得。
<例>
SELECT name,max(price) FROM account WHERE name = "ランチ";
結果
↓

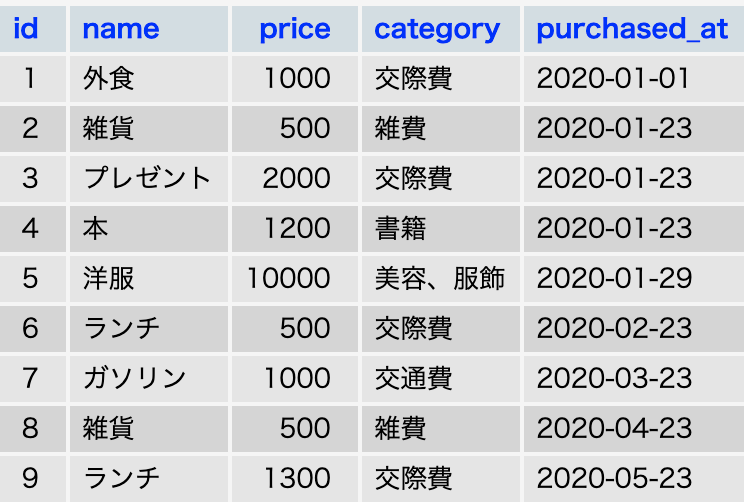
データのグループ化
GROUP BYを用いるとデータをグループ化することができる。
指定したカラムで、完全に同一のデータを持つレコード同士が同じグループになる。
SELECTのカラム名(GROUP BYのカラム名)は、複数選択可能。
SELECT 集計関数,カラム名 FROM テーブル名 GROUP BY カラム名(SELECTと同じ);
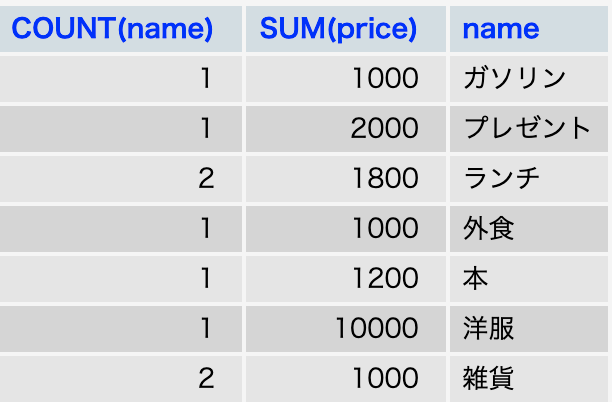
<例>合計金額と同じカラム名をグループ化
SELECT COUNT(name),SUM(price), name FROM account GROUP BY name;
結果
↓
WHEREとの併用
WHEREをGROUP BYと併用すると以下の順で実行される。
・検索 WHERE
WHEREでカラムの値が一致するデータが検索される
↓
・グループ化 GROUP BY
指定されたカラムでグループ化する
↓
・関数 COUNTなどの関数
グループ化されたデータを関数で処理
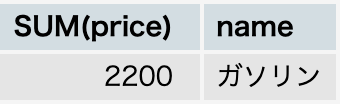
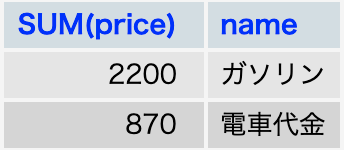
<例>交通費の使用途ごとに合計金額を出力する。
SELECT SUM(price),name FROM account WHERE category = "交通費" GROUP BY name;
結果
↓
HAVINGとの併用
グループ化したデータからさらに絞り込んで検索する構文。
・検索 WHERE
WHEREでカラムの値が一致するデータが検索される
↓
・グループ化 GROUP BY
指定されたカラムでグループ化する
↓
・関数 COUNTなどの関数
グループ化されたデータを関数で処理
↓
・HAVING
指定した条件のデータを検索。
<例>
SELECT SUM(price),name FROM account WHERE category = "交通費" GROUP BY name HAVING SUM(price)>1000;
結果
↓